








Introduction:
All living bodies are composed of several lifeless substances which are present in their cells in a very complex but highly organised form.
These life less substances are called biomolecules.
Carbohydrate proteins, enzymes, lipids, vitamins, hormones, nucleic acid, amino acids fats are the common examples of biomolecules.
These biomolecules combine in a specific manner to produce life and one related to living organism, in the following sequence.
Living organism → Organs → Tissues → Cells → Organelles → Biomolecules
Many of these biomolecules are biopolymers e.g., starch, proteins, nucleic acids are condensation polymers of simple sugars (glucose), amino acids and nucleotides respectively.
Most of the biochemical reactions take place in dilute neutral solutions (pH ≈ 7) at body temperature (≈ 370C) and 1 atmospheric pressure.
These biochemical reactions are very complex and highly selective.
Before, discussing the chemistry of biomolecules, let us first know about the sources of energy in plants and animals which are responsible for their growth and maintenance.
The branch of science that deals with the study of the chemical composition and the structure of living organism and also various chemical changes taking place within them, is called biochemistry.
The cell and energy cycle:
The cell is a fundamental structural and functional unit of living organisms. i.e., Every living being is made up of cells.
It is too small to be seen with the nacked eyes. However these can be seen with the help of microscope.
Thus the cells are smallest packets of chemicals essential for life. The most important characteristic of the cell is its ability to grow and divide to produce new cells. These daughter cells can further divide to produce new progeny of cells.
Cells may be combined to form tissue and finally organisms. i.e.,
Cell → Tissues → Organs → Organisms
A living cell contains about 50 elements. The eleven most abundant elements in living organisms are O, C, H, N, Ca, P, K, S, Cl, Na & Mg. The first four elements i.e., oxygen, carbon, hydrogen and nitrogen together account for 96% of adult total mass.
The most abundant substance in living cell is water which amounts to about 70% of the body weight.
In addition, to water, the cell contains a large number of carbon compounds. These compounds can be divided into two classes.
The compounds of first class are small molecules having masses in the range of 100 to 1000 and containing upto 30 carbon atoms. These are found free in solution in the cytoplasm of the cell. They form number of intermediates from which the molecules belonging to the second class are synthesised.
The compounds of the second class are macromolecules. Among these the important are carbohydrates, proteins, lipids and nucleic acids.
In the view of energy cycle, a large number of chemical reactions are occurring in a living system.
The chemical reactions of a living system can be divided into main two types as catabolic and anabolic reactions (i.e., anabolism).
These two reactions that is catabolism (degradation) and anabolism (synthesis) are collectively known as metabolic reactions (metabolisms).
Catabolic reactions are usually accompanied by release of energy whereas anabolic reactions require energy to occur.
Therefore, the catabolic reactions serve to provide both energy for various cellular functions.
There are some reactions (functions) within the chemical cells that are neither anabolic nor catabolic. e.g., uptake of nutrients from the environment, the movement of the cells, conductance of nerve impulses, contraction of muscles etc.
Thus, just as we need energy to run, jump and think, cells also need a ready supply of cellular energy to carryout many functions which support these activities.
The cells need energy for active transport, to move molecules between the environment and the cell, across cells or within cells, to carryout cell division, to perform electrical work on conduction of nerve impulse etc.
The energy needed for these cellular reactions is mainly provided by oxidation of biomolecules such as carbohydrates (i.e., glucose), lipids etc.
This oxidation takes place in a complex and controlled way by means of enzymes which are biocatalysts.
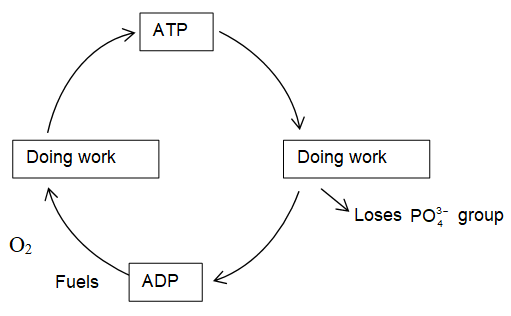
A part of energy obtained by oxidation of biomolecules is stored in the living cells in chemical compound called adesonosine triphosphate (ATP). It is regarded as energy currency of living cells because it can trap, store and release small packets of energy with ease.
Cellular Energetics:
According to thermodynamics, only those reactions are feasible which involve loss in free energy (ΔG = – ve).
Such reactions which proceed with decrease in free energy are called exergonic reactions (ΔG < 0) and they are spontaneous reactions in nature.
e.g., (i) Stepwise degradation of sugar to CO2 and H2O.
(ii) Conversion of ATP to ADP is highly exergonic.
Such reactions which proceed with increase in free energy are called endergonic reactions (ΔG > 0) and are non-spontaneous in nature. The appear to be thermodynamically for bidden.
Nevertheless, such endergonic reactions with increase in free energy (ΔG > 0) can be made to proceed in desired direction by coupling them with some suitable exergonic reactions with decrease in free energy (ΔG < 0).
e.g., (i) A → B ; ΔG1 > 0 (ΔG1 = + ve) 50 kJ mol–1
(ii) R → P ; ΔG2 < 0 (ΔG2 = – ve) – 80 kJ mol–1
When the reaction (i) is coupled with reaction (ii) the overall reaction has negative free energy change and therefore, occurs spontaneously.
(i) + (ii) A + R → B + P; ΔG = – 30 kJ mol–1
All energy requiring cellular reactions proceed by this principle of coupling to an energy releasing.
The common reaction providing energy in cellular reaction is hydrolysis of adenosine triphosphate (ATP), and it is coupled with other non spontaneous reactions. Thus, ATP acts as the centre of all activities of cell.
Photosynthesis and energy:
The energy for life processes basically comes from sun. During photosynthesis, green plants absorb sun light to prepare glucose and oxygen from atmospheric CO2 and H2O.
Photosynthesis is a complex process which occurs in several steps and the net reaction is
.
The oxygen produced in photosynthesis is the source of all the oxygen in our atmosphere.
Thus, photosynthesis occurs in the chloroplasts of the cell and involves two reactions i.e., light and dark reactions.
Light reactions occur in presence of light energy following by dark reaction. In light reaction the green pigment chlorophyll present in plants absorbs the sunlight. This absorbed energy is used up to synthesize energy rich molecule (ATP) and oxidise water to oxygen.
On the other hand dark reactions can occur in dark. Because they donot depend on light. (occurs continuously).
Here ATP undergoes hydrolysis with liberation of high energy which carries the dark reactions i.e., dark reaction proceeds on high energy produced by the hydrolysis of ATP.
In fact, ATP drives the dark reactions which convert CO2 and hydrogen (comes from H2O) into glucose and other carbohydrates.
The living plants may convert the glucose produced during photosynthesis into disaccharides, polysaccharides, starches, cellulose, proteins or oils.
The end product depends on the type of plants involved and complexity of its biochemistry.
Plants, thus are primary source of energy for animals and humans. This can be represented by oxidation of glucose which is reverse of photosynthesis.
Respiration is the reverse process of photosynthesis. A part of this energy (ΔG0 = – 2880 kJ mol–1) is utilized while a part of it is stored leading to the next reaction.
ATP is a energy rich molecule. This is because of the presence of four negatively charged oxygen atoms very close to each other. These four negatively charged O-atoms experience very high repulsive energy.
Carbohydrates:
Carbohydrates are mainly compounds of carbon, hydrogen and oxygen. The name ‘carbohydrate’ arose from mistaken belief that the substances of this kind were hydrates of carbon with the general formula in which hydrogen and oxygen existed in the ratio of 2 : 1 as in water molecule.
For example glucose, sucrose, starch cellulose etc satisfy this definition/formula
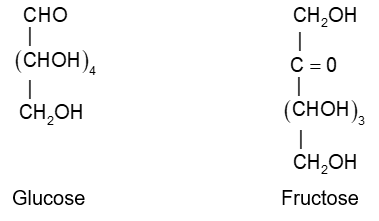
Glucose
Sucrose :
Starch, cellulose:
However, a number of compound have been reported which are carbohydrates by chemical behaviour but do not obey the formula of hydrates of carbon, Cx(H2O)y.
e.g., rhamnose (C6H12O6)
2-deoxyribose : C5H10O4.
Thus it is to be noted that all compound possessing the formula are not necessarily carbohydrates.
e.g., compounds like formaldehyde, acetic acid, lactic acid, etc are not carbohydrates but have the formula of hydrates of carbon. i.e.,
Formaldehyde HCHO or C(H2O)
Acetic acid CH3COOH or C2(H2O)2
Lactic acid CH3CH(OH)COOH or C3(H2O)3
Thus, based on structural evidences and chemical reactivity carbohydrates are optically active polyhydroxy aldehydes or ketones or the compounds which yield them on hydrolysis.
e.g., glucose, fructose, sucrose, maltose etc.
Classification of carbohydrates

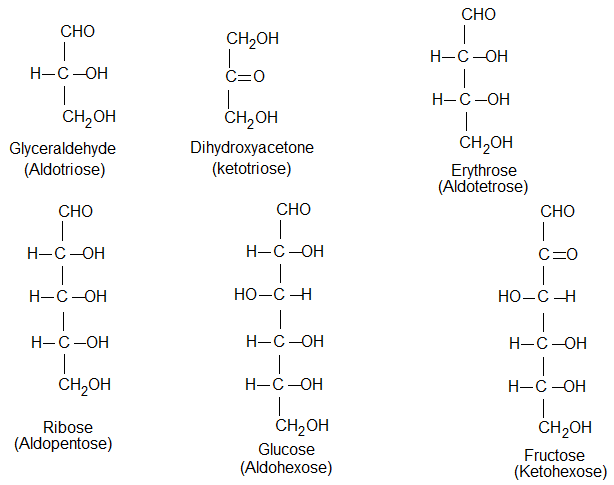
Monosaccharides: GF: CnH2nOn (where n = 3 to 9):
These are the simplest carbohydrates and can not be hydrolysed to give still simpler carbohydrates.
Monosaccharides containing aldehyde group (-CHO) are called aldoses while those with ketonic group (> C = 0) are called ketoses.
Table: Nomenclature of monosaccharide
|
Carbon atoms |
General terms |
Aldehydes |
Ketones |
|
3 |
Triose |
Aldotriose |
Ketotriose ex.Dihydroxyacetone |
|
4 |
Tetrose |
Aldotetrose ex.Erythrose, Threose |
Ketotetrose ex.Erythrulose |
|
5 |
Pentose |
Aldopentose ex. Arabinose, Ribose Xylose, Lyxose |
Ketopentose ex. Ribulose, Xylulose |
|
6 |
Hexose |
Aldohexose ex. Glucose, Galatose |
Ketohexose ex. Fructose, sorbose |
|
7 |
Heptose |
Aldoheptose |
Ketoheptose |
|
8 |
Octose |
Aldooctose |
Ketooctose |
The most important naturally occurring monosaccharide are pentose and hexoses. E.g., Ribose is a common pentose while glucose and fructose are common hexoses.
Structure of monosaccharides: GF. CnH2nOn
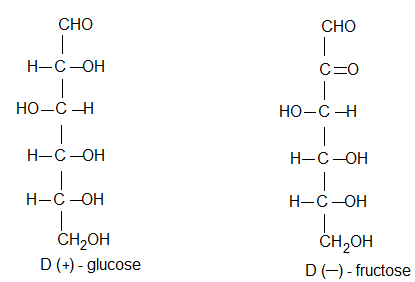
D and L – configurations:
The sugars are divided into two families. The D-family and L-fifamily which have definite configurations.
According to Rosanoff (1906) arbitrarily. These 2-configurations arerepresented with respect to glyceraldehyde as the standard. The glycoraldehyde may be represented by two enantiomeric forms as shown below.
By convention, molecule is assigned D-configuration if the -OH group attached to the carbon adjacent to -CH2OH (last chiral carbon) is on the right hand side (RHS) irrespective highest numbered of the position of other groups.
On the other hand the molecule is assigned L-configuration if the -OH group attached to the carbon adjacent to the -CH2OH group is on the left hand side (LHS).
It has been found that all naturally occurring sugars belong to D-series e.g., D-glucose, D-ribose and D-fructose.
By convention, molecule is assigned D-configuration if the -OH group attached to the carbon adjacent to -CH2OH (last chiral carbon) is on the right hand side (RHS) irrespective highest numbered asymmetric of the position of the other groups.
On the other hand the molecule is assigned L-configuration if the -OH group attached to the carbon adjacent to the -CH2OH group is on the left hand side (LHS).
It has been found that all naturally occurring sugars belong to D-series e.g., D-glucose, D-ribose and D-fructose.
It may be noted that the letter D- and L – do not stand for dextrorotatory or laevorotatory. They indicate only the configuration not the direction of rotation of plane of polarised light, whereas the ‘+’ and ‘-’ signs only specify the direction of rotation of the plane of polarised light by a particular enantiomer but these ‘+’ & ‘-’ sings do not give indication of attachment of -OH group and H around the asymmetric carbon atom.
The stereochemistry of all sugars is determined with reference to D-or L-glyceraldehyde.
Presence of asymmetric carbon atoms:
Except ketotriose (dihydroxyacetone) all aldoses and ketoses i.e., monosaccharides contain asymmetric (chiral) carbon atoms and are optically active. E.g., glucose has four chiral carbon atoms.
Number of optically active stereo isomers depend on the number of asymmetric (chiral) carbon atoms present in a molecule of monosaccharide.
Number of isomers = 2n, where n = no. of chiral carbon atoms.
|
Carbon atoms |
General terms |
No. of asymmetric carbon atoms |
No. of isomers |
|
|
3 |
Trioses |
1 |
2 |
|
|
4 |
Tetroses |
2 |
4 |
|
|
5 |
Pentoses |
3 |
8 |
|
|
6 |
Hexoses |
4 |
16 |
|
The carbon atoms of an aldose are numbered starting from the aldehyde group (-CHO) and that of ketose from that end which closest to the ketonic group (x = 0).
Illustration 1: Why are carbohydrates generally optically active?
Solution: Carbohydrates are generally optially active because they have one or more chiral carbon atoms.
Glucose (Dextrose; Grape sugar):
Glucose occurs in nature in free as well as in the combined from. It is present in sweet fruits and honey. Ripe grapes contain ~ 20% of glucose.
Preparation of Glucose:
1. From sucrose (cane sugar):
If sucrose is boiled with dilute HCl or H2SO4 in alcoholic solution, glucose and fructose are obtained in equal amounts.
2. From starch: Commercially glucose is obtained by hydrolysis of starch by boiling it with dilute H2SO4 at 393 K. Under pressure.
Structure elucidation and properties of glucose:
1. MF = C6H12O6
2. Glucose has one aldehyde group, one primary (-CH2OH) and four secondary (-CHOH) hydroxyl groups and gives the following reactions.
Presence of 5 – ‘OH’ groups:
(1) Acetylation: Acetylation of glucose with acetic anhydride gives glucose pentaacetate.
Hence, this reaction indicates that glucose molecule has 5 ‘OH’ groups.
(ii) Presence of carbonyl group:
Glucose reacts with hydroxylamine to give monoxime and adds a molecule of hydrogen cyanide to give a cyanohydrin.
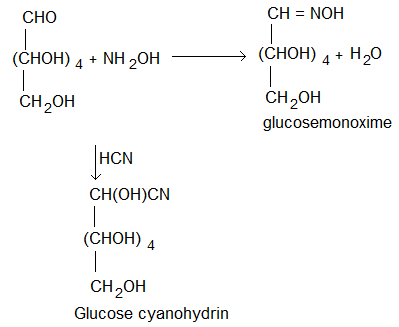
These reactions suggest that glucose has one carbonyl (> C = 0) group.
(iii) Reducing property: Glucose reduces ammonical silvernitrate solution (Tollen’s reagent) to metallic silver and also fehling’s solution to reddish brown cuprisms oxide and itself gets oxidise to gluconic acid.
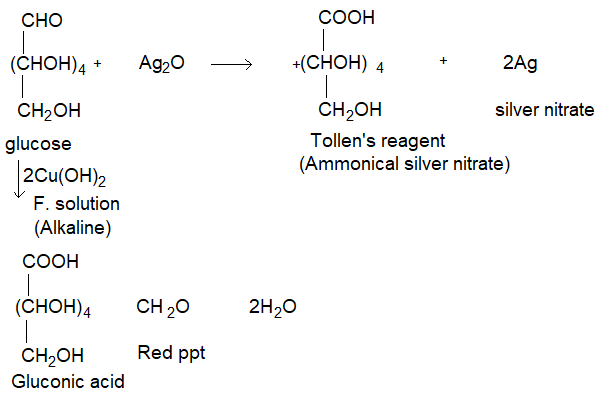
On these reactions confirm that the carbonyl group present in glucose is aldehyde group.
Even bromine water or an alkaline solution of iodine oxidises only the aldehyde group of glucose to give glucose acid. (-CHO to -COOH)
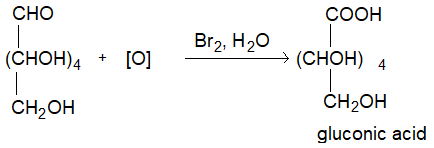
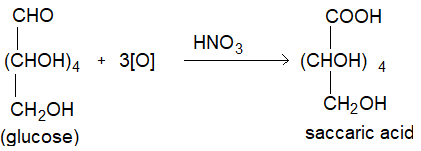
(iv) Oxidation: On oxidation with nitric acid glucose as well as gluconic acid both yield a dicarboxylic acid, saccharic acid. This indicates the presence of a primary alcoholic group in glucose as well as -CHO group.
(v) Glucose on prolonged heating with HI forms n-hexane, suggesting that all the 6 carbon atoms in glucose are linked linearly.
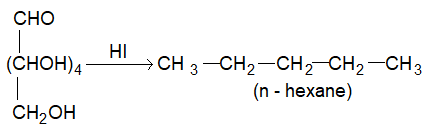
This reaction suggest that all six carbon atoms in glucose are linearly linked.
(vi) D-glucose reacts with phenol hydrazine to give glucose phenylhydrazone. If excess of phenyl hydrazine is used a dihydrazone, known as of a zone is obtained which is called glucose a zone.
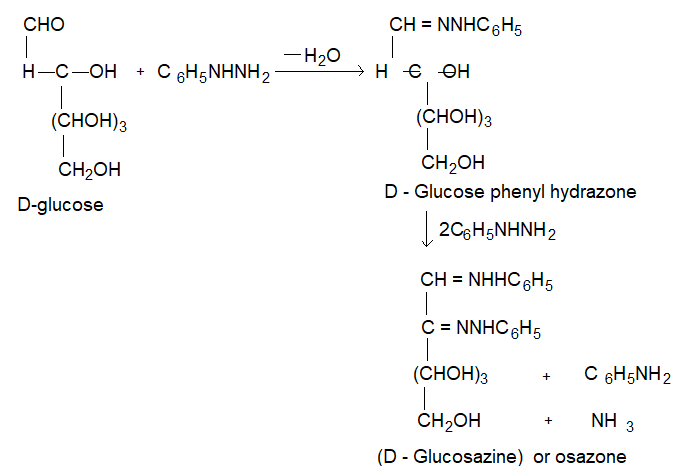
yellow crystallin compound, m = 2.50C.
(vii) On heating with concentrated solution of NaOH, glucose first turns yellow, then brown and finally resinifies.
Glucose yellow → Brown → resinous mass.
On the other hand, with dilute solution of NaOH, glucose undergoes a reversible isomerization and is converted into a mixture of D-glucose,
D – mannose and D – fructose.
D – glucose D – mannose D – fructose
This reaction is known as Lobry de Bruyn – van Ekenstein rearrangement:
• Same mixture is obtained even if mannose or fructose are treated with alkali.
• It is probably on account of this isomerization that fructose reduces fehling’s and Tollen’s reagents in the alkaline medium although it does not contain -CHO group.
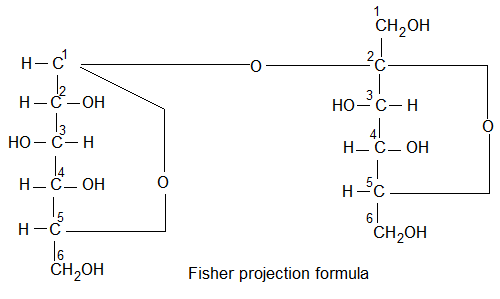
(viii) Confirmation: Based on the above experimentally observed chemical changes glucose has been assigned a straight chain or open chain structure. It was proposed by Baeyer and configuration of D-glucose proved by Emil Fishcher. The fischer projections for D and L glucose are shown below.
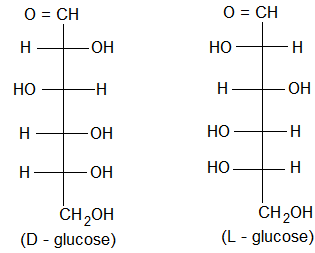
Note: The stereochemistry of all sugars has been determined by relating it to that of D or L glyceraldehyde.
Cyclic structure of D – Glucose:
The open chain structure of glucose proposed by Baeyer explained most of its properties. However it could not explain the following.
(i) Why glucose does not respond to schiff’s test like other aldehydes and it does not react with sodium hydrogen sulphite and ammonia, through it has an aldehydic group (-CHO).
(ii) Why pentaacetate of glucose does not react with hydroxylamine. Though it has -CHO group. i.e., indicating absence of -CHO group.
(iii) Mutarotation: (Why there is mutarotation)
The spontaneous change in specific rotation of an optically active compound is called mutarotation.
Glucose was crystallised from a concentrated solution at 300C, gives α – form of glucose m.p. 1460C [α]D = (+) 1110.
On the other hand, glucose crystallised from a hot saturated aqueous solution at a temperature greater than 980C gives β – form of glucose mp 1500C [α]D = (+) 19.20.
The two forms known as anomers of glucose differ from each other in the stereochemistry at C – 1. (i.e., anomeric carbon or glycosidic carbon).
If each of them is separately dissolved in water and allowed to stand their specific rotations gradually change and reach to a specific constant value + 52.50 and the change is quickened by a trace of acid or base. This spontaneous change in specific rotation [α]D of an optically active compound is called mutarotation.
α – D – (+) equilibrium mixture β – D (+) glucose
[α]D (+) 11.10 +52.50 (+) 19.20
36% 64%
(iv) When glucose is treated with methanol in the presence of dry hydrogen chloride gas, it yields two isomeric monomethyl derivatives known as methyl α – D – glucoside and methyl. β – D – glucoside. These glucosides confirm the existence of D – glucose in two α & β forms.
These glycosides do not reduce Fehling’s solution and also do not react with hydrogen cyanide or hydroxylamine indicating the absence of a free -CHO group.
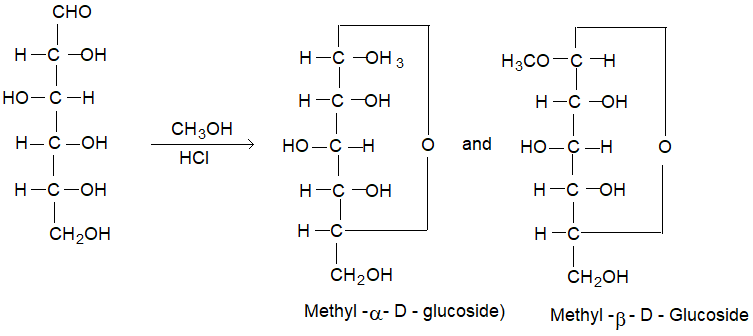
In cyclic configuration the anomeric carbon C – 1 becomes asymmetric and newly formed ‘OH’ on it may be either on the left or on the right in Fischer projection, resulting in two isomers known as anomers.
The anomer having -OH group to the right side of C – 1 is known as α – D glucose and that with -OH group to the left side is known as β – D glucose.
These two forms are not mirror images of each other. Hence, are not enantiomers.
Pyranose structure: (Formed between C1 & C5)
The six membered cyclic configuration of glucose is called pyramose structure (α or β) as it is similar to pyran, a six membered ring with one oxygen and five carbon atoms in the ring. This six membered pyranose structure of glucose was established by R.D. Haworth and Hirst and known as pyranose structure of Haworth structure.
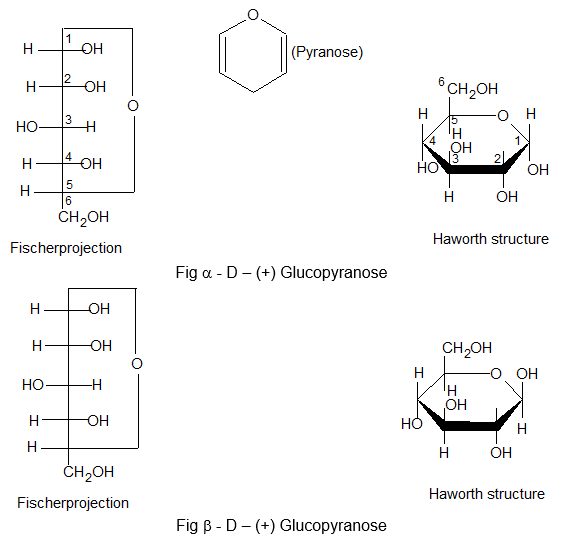
In Haworth structure of glucopyramose the lower thickned edge of the ring is nearest to the observer.
The group projected to the right in Fischer projection are written below the plane of the ring in Haworth structure and those on the left are written above the plane of the ring.
The Haworth structure is identical to Fischer projection of glucose.
The cyclic structure of glucose account for the facts
(i) The existence of α, β – isomers of glucose.
(ii) Mutarotation
(iii) Glucose and other aldoses do not give certain characteristic reactions of aldehydes as mentioned in structure elucidation.
Note: Fructose also undergoes mutardation.
Illustration 2: How do anomers differ from epimers?
Solution: Carbohydrates which differ in configuration at the glycosidic carbon (i.e., C1 in aldoses and C2 in ketoses) are called anomers. The carbohydrates which differ in configuration at any asymmetric carbon atom other than glycosidic carbon are called epimers. For example, α – D- glucose and β – glucose are anomers. (differ at C1; glycosidic carbon). On the other hand, glucose and mannose are apimers (differ in configuration at C2).
Illustration 3: Why is glucose given to patients under exhaustion?
Solution: Glucose is an on instant source of energy and hence is given to patients under exhaustion.
Interconversion of Monosaccharides:
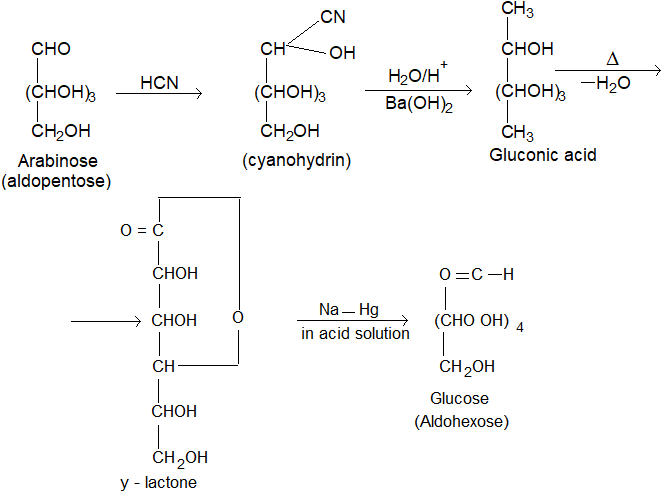
1. Conversion of aldopentose into aldohexose (Killiani Fischer synthesis): The conversion of aldose to the next higher member involves the following steps.
(i) Formation of a cyanohydrin.
(ii) Hydrolysis of -CN to -COOH forming aldonic acid.
(iii) Conversion of aldonic acid into lactone by heating.
(iv) The lactone is finally reduced with sodium amalgam or sodium borohydride to give the higher aldose.
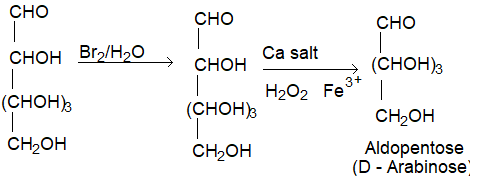
(II) Conversion of aldohexose into aldopentose (Ruff degradation):
a) An aldose can be converted to next lower member by Ruff degradation. It involves two steps.
(i) Oxidation of the aldose to aldonic acid by using bromine water.
(ii) The aldonic acid is treated with CaCO3 to give the calcium salt which is then oxidised by Fenton’s reagent (H2O2 + Ferric sulphate) to form the next lower aldose.
(b) By Wohl’s Method: It involves the following steps.
(i) Formation of oxime with hydroxylamine.
(ii) Heating of oxime with acetic anhydride undergoes dehydration into cyano compound whereas the – OH groups get acetylated.
(iii) The acetyl derivative is warmed with ammonical silver nitrate which removes the acetyl group by hydrolysis and eliminates a molecule of HCN.
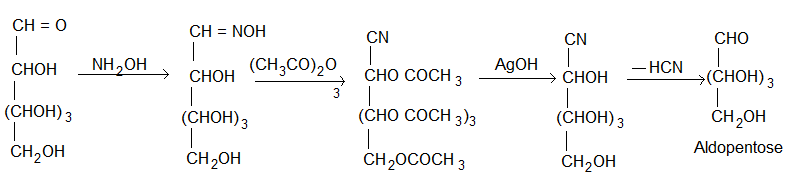
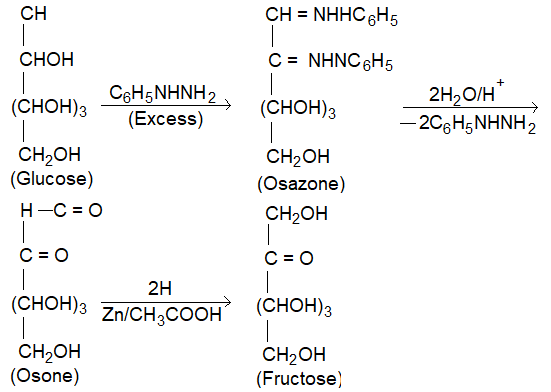
(III) Conversion of Glucose into fructose: It involves the following steps.
(i) Treatment of aldose with excess of phenylhydrazine to Osazone.
(ii) Hydrolysis of osazone with dil HCl to form oson.
(iii) Reduction of ozone with zinc and acetic acid to form ketose.
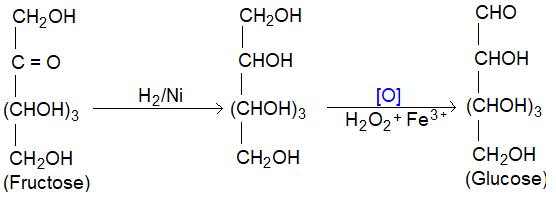
(IV) Conversion of fructose into Glucose: It involves two steps
(i) Reduction of > C = O group with H2/Ni to -CHOH group.
(ii) Oxidation with Fenton’s reagent to form aldose.
Disaccharides: GF. C12H22O11
The disaccharides are composed of two molecules of monosaccharides. E.g., sucrose, lactose maltose etc.
On hydrolysis with dilute acids or enzymes they yield two molecules of either the same or different monosaccharides e.g.,
In disaccharides, monosaccharide units are joined together by glycoside linkage.
A glycoside linkage is formed when -OH group of hemiacetal carbon of one monosaccharide condense with a -OH group of another monosaccharide giving -O- bond.
(i) If this glycosidic linkage involves the carbonyl functions of both the monosaccharide units he resulting disaccharide would be non-reducing. e., They contain stable acetal or ketal structures which can not be opened into a free carbony group. E.g., sucrose.
(ii) If one of the carbonyl functions in anyone of the monosaccharide unit free, the resulting disacchalide would be reducing sugar i.e., they contain cyclic hemiacetal or hemiketal or structure in equilibrium with open chain forms having a free – CHO or x = 0 group.
Sucrose or cane sugar (C12H22O11):
It is our common table sugar and is obtained from sugar cane and sugar beets.
It is also known as beet sugar and found in all photosynthetic plants. i.e., widely distributed in plants.
Properties:
It is colourless, odourless, crystalline, water soluble sweet substance mp = 185 – 1860C.
It is slightly soluble in alcohol and insoluble in ether.
It’s aqueous solution is dextrorotatory but does not show mutarotation.
It is a non-reducing sugar as it does not reduce Tollen’s or Fehling’s reagents.
Sucrose, on heating slowly and carefully melts and then if allowed to cool, it solidified to pale yellow glassy mass called ‘Barley sugar’.
When heated to 2000C, it loses water to form brown amorphous mass called caramel. On strong heating, it chars to almost pure carbon giving smell of burnt sugar.
Structure of sucrose / cane sugar:
• Sucrose is composed of α – D – glucopyranose unit and a β – D – fructofurnose unit.
Haworth (1927) suggested the following structure for sucrose.
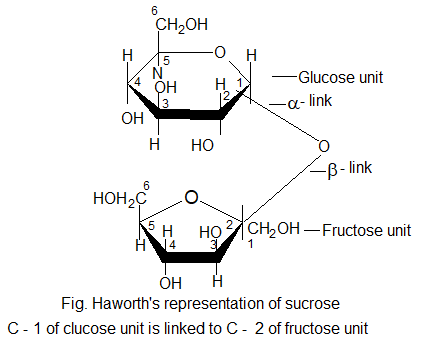
Inversion of cane sugar:
On hydrolysis with dilute acids or by enzyme invertase 2 sucrase can sugar gives equimolar mixture of D – (+) – glucose and D – (- ) fructose.
Sucrose solution is dextrorotatory but after hydrolysis gives dextrorotatory glucose and laevo rotatory fructose and the mixture become laevorotatory because laevorotation of fructose (-92.40) is more than dextrotration of glucose (+ 52.50).
• Therefore, the net specific rotation of an equimolar mixture of diaglucose and D (-) fructose is -850.
Thus, hydrolysis of sucrose brings about a change in the sign of rotation from dextro (+) to laevo (-) i.e., specific rotation changes from + 66.50 to – 19.950 viz d to l. Such a change is known as inversion of sugar and the mixture is known as invert sugar.
Sucrose solution is fermented by yeast when the enzyme invertase hydrolyses sucrose to glucose and fructose; enzyme, zymase converts these monosaccrarides to ethyl alcohol and carbon dioxide.
Uses:
(i) As sweetening agent for various food preparations, jams, syrups sweets, etc.
(ii) IN manufacture of sucrose octa acetate required to denature alcohol, to make paper transparent and to make anhydrous adhesives.
Maltose (Malt sugar, C12H22O11):
It is a disaccharide and obtained by partial hydrolysis of starch by diastase and enzyme present in malt (sprouted barley seeds).
On hydrolysis one mole of maltose yields two moles of D-glucose.
It is a reducing sugar.
Structure of maltose:
In the structure of maltose two glucose pyranose units are linked through a α – glucopyranose units are linked through a α – glycosidic linkage between C – 1 of one unit and the C – 4 of another.
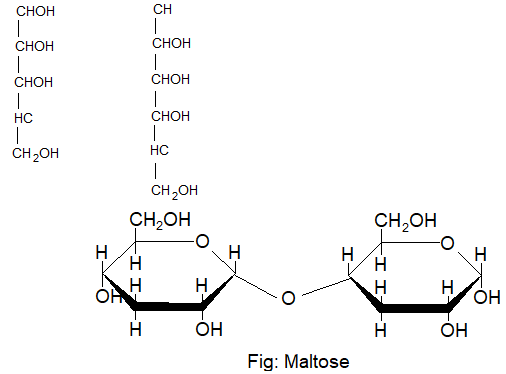
Lactose / Milk sugar (C12H22O11):
Lactose is composed of D-glucose and D-galactose linked together by 1, 4 – β – glycosidic linked.
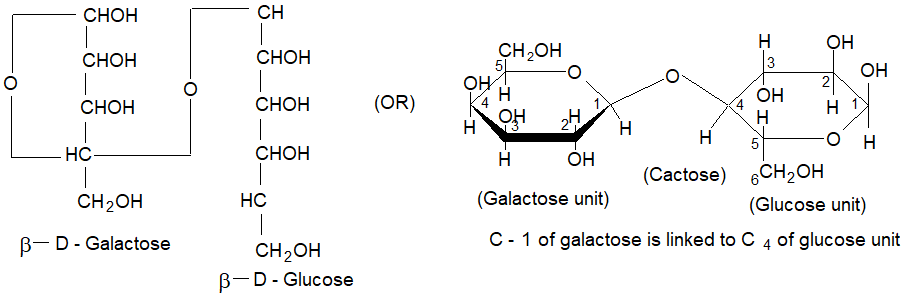
Polysaccharides:
Carbohydrates containing large number (hundreds or even thousands) of monosaccharide units are joined together by glycoxidic linkages are called polysaccharides. E.g., Starch, cellulose, dextrin, glycogen, etc. However, starch and cellulose are most important of the polysaccharides.
Starch / Amylum (C6H10O5):
Starch occurs in all plants, particularly in their seeds.
The main sources are wheat, maize, mica, potatoes, barley and sorghum, legumes and vegetables.
Basically starch occurs in the form of granules, which vary in shape and size depending on their plant sources.
Thus, starch is a white amorphous powder almost insoluble in cold water but relatively more soluble in boiling water.
It’s solution in water gives blue colour with iodine solution. The blue colour disappears on heating and reappears on coding.
On hydrolysis with dilute acids or enzymes starch breaks down to molecules to variable complexity (n > n), maltose and finally D- glucose.
Starch does not reduce Fehling solution or Tollen’s reagent and does not form osazone. These facts indicate that all hemiacetal -OH group of glucose units at C – 1 are linked with glycosidic linkages. i.e., anomeric – OH group has been replaced by an alkoxy group.
Thus, we can say that glycosides are carbohydrates derivatives obtained by replacement of anomeric – OH group by some other substituent and are termed as – O, N – S – glycosides etc, depending on the atom attached to the numeric carbon.
Composition of starch: Starch is the polymer of D(+) glucose and consists of two components i.e.,
Starch is a mixture of the saccharides, amylose and amylopectin.
Natural starch has approximately 10 – 20% of amylose and 80 – 90% of amylopectin.
(i) Amylose:
Amylose is a water soluble fraction of starch and gives blue colour with iodine.
Amylose is a linear polymer of 100 – 3000 D (+) – glucose units joined together by α – glycosidic linkages involving C – 1 of one glucose and C – 4 of next.
It’s molecular mass can range from 10,000 to 500,000.
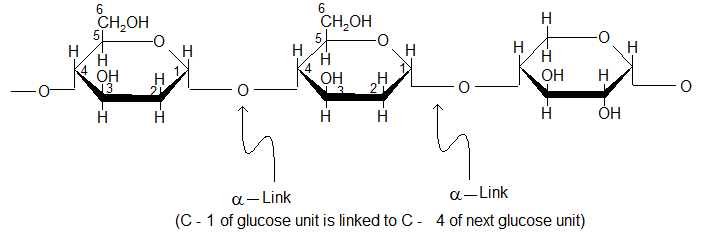
(ii) Amylopectin: Amylopectein is a water insoluble fraction of starch and it does not give blue colour with iodine.
Amylopectin is a branched chain polymer (polysaccharide) of D (+) – glucose units joint together by (1, 4) and α (1, 6 -) glycosidic linkages i.e., it is composed of chains of 25 – 30 D – glucose units joined by α – D – glycosidic linkages between C – 1 of one glucose unit and C – 4 of the next glucose unit similar to amylose and however, branched with each other by 1, 6 – linkages.
For simplicity it may also be represented as shown below.
Starch is used as the principal food storage of glucose energy. It is hydrolysed by enzyme amylase present in saliva. The end product is glucose which is an essential nutrient.
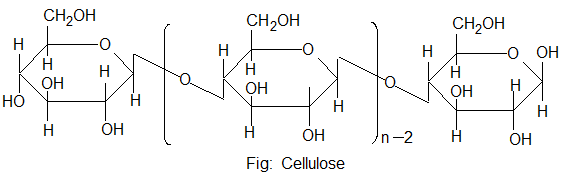
2. Cellulose:
Cellulose is the chief structural components of plants or vegetable matter and prepared during photosynthesis.
Wood contains 45 – 50% while cotton contains 90 – 95% cellulose.
In fact more than 50% of all the living matter is cellulose.
It is colourless amorphous solid which is insoluble in water and in most of the organic solvents and decomposed on heating but does not melt.
It is largely linear and its individual strands align with each other through multiple hydrogen bonds. This lands rigidity to its structure. It is thus used effectively as a cell wall material.
Cellulose does not reduce Tollen’s reagent or Fehling’s solution. However it dissolves in ammoniacal copper hydroxide solution (Schweitzer’s reagent). It is also dissolved in a solution of ZnCl2 in HCl acid.
It does not form osazone and is not fermented by yeast.
It is not hydrolysed as easily as starch but on heating with dilute sulphuric acid under pressure, it is completely hydrolysed into D-glucose.
On the other hand, cellulose on trating with conc H2SO4, slowly passes into solution, which on dilution with water precipitates a starch like substance amyloid called parchment paper.
The cattle, sheeps, goats and other ruminant mammals can feed directly cellulose as they have digestive enzymes cellulase, which breaks down cellulose into glucose.
Structure of cellulose:
Cellulose is a straight chain polysaccharide composed of only D-glucose units, which are joined by β – glycolsidic linkages between C – 1 of one glucose unit and C – 4 of the next glucose unit.
The number of D- glucose unit in cellulose ranges from 300 to 250,000 and its molecular mass is about 50,000 – 500,000.
Uses:
(i) In the manufacture of cloth (cotton), canvas, gunny bags (jute) and papers (wood, bamboo, straw, etc.).
(ii) In the manufacture or rayon and plastic Rayon is a artificial silk which is manufactured from cellulose acetate.
(iii) In the manufacture of gun cotton (explosive), medicine, paints and lacquers in the form of cellulose nitrate.
Cellulose nitrate also used in the manufacture of celluloid with camphor. Celluloid is used in the making of toys, decorative articles and photographic films.
Ethyl cellulose is used in plastic coats and films.
On treatment with conc NaOH cellulose forms a translucent mass which imparts a silky lustre to cotton the process is called mercerisation and cotton so produced is called mercerised cotton.
In addition to starch and cellulose, a number of other polysaccharides are used as food components. These are the gums and pectens.
Gums are polysaccharides made up of more than one type of monosaccharides. They are used for thickening and improvement of texture in food industry.
Pectines are found in fruit skins and are extracted by boiling. Jelly preparations contain pectin dissolves in a fruit juice.
The pectin causes jelly to set into a semi solid.
Functions of Carbohydrates:
(i) Monosaccharides play on important role in all the metabolic reactions of the body.
(ii) They act as biofuels to provide energy for functioning of living organism: In human system, all carbohydrates except cellulose can serve as the main source of energy. The higher carbohydrates which are taken as food are first hydrolysed to glucose by the enzymes present in the human and animal digestive systems.
Glucose on slow oxidation yield large amount of energy for living organism.
In order to fulfil the emergency requirements our body also stores some of the carbohydrates, our body also stores some of the carbohydrates (monosaccharides) as glycogen (animal starch) in the liver which on hydrolyses gives glucose.
Thus, one gram of carbohydrates yields 4.0k cal energy.
(iii) Carbohydrates form structural material for cells. E.g., cellulose is present in the cell walls of the plant cells.
(iv) Ribose and deoxyribose sugars form nucleic acids like RNA and DNA respectively.
Illustration 4: Amylose and cellulose are both straight chain polysaccharides containing only D – glucose units. What is the structural difference between the two?
Solution: In amylose, D-glucose units are joined together by α – glucosidic linkages involving C – 1 of one glucose molecule and C – 4 of the next glucose molecule. In cellulose, D – glucose units are joined together by β – glycosidic linkages between C – 1 of one molecule and C – 4 of the next glucose unit.
Proteins and Amino acid:
Proteins: Protoplasm of plant or animal cell contains 10 – 20% nitrogenous.
Proteins are nitrogenous high molecular mass complex biopolymers of amino acids present in all living cells, i.e., they are a class of biologically important compounds.
The name protein is derived from the Greek word proteios meaning of growth and maintenance of life. E.g., As enzymes there catalyse biochemical reaction, as hormones, they regulate metabolic processes for example insulin controls the level of sugar in the blood stream and as antibodies. They protect the body against toxic substances.
Despite their wide range of functions, all proteins have something in common with another.
Hence, they are condensation polymers (make up of linking together in various combinations, a number of different simple monomeric units) α – amino acids.
All proteins contain the elements such as carbon, hydrogen, oxygen, nitrogen and sulphur.
Some of these may also contain phosphorus, iodine and trace of metals like iron, copper, zinc and manganese.
All proteins on partial hydro lysis give peptides of varying molecular mass which on complete hydrolysis give amino acids.
Proteins are naturally occurring polypeptides that contain more than 50 aminoacids units and generally 100 – 300 units.
Silk, hair, skin, connective tissues, most of the enzymes, hormones they are examples for protein.
Aminoacids:
An amino acid is a bifunctional organic compound and they contain both carboxyl (-COOH) and amino (-NH2) functional groups because these are amino substituted carboxylic acid.
On the basis of relative position of the two functional groups in the alkyl chains the amino acids can be classified as α, β, γ, δ and so on. E.g.,
Out of these α – amino acids are most important as they are building block of bioproteins which are very essential for us.
All the amino acids that form proteins possess primary amino groups except one that is prolive a secondary amine.

Nomenclature of Amino Acids:
All amino acids have trival names as well as IUPAC names although, they are known by trival names/common names because which are not comber some.
e.g., NH2CH2COOH common name: Glycine
IUPAC name : α – Aminoacetic acid or 2 Amino ethanoic acid
NH2CH2COOH is better known as glycine rather than α – amino acetic acid or 2 – amine ethanoic acid.
These trival names usually reflects the property of that compound or its source.
e.g., glycine is so named because it has sweet taste (in Greek glycos = sweet) and tyrosine was first obtained from cheese (in Greek : tyros = cheese).
For the sake of simplicity, amino acids are generally represented by a three better symbol, sometimes one letter symbol is also used.
There are more than 700 different amino acids known to occur naturally but a group of 20 of them along with 3 letter and 1 – letter symbols are give in the table.
Table : Commonly occurring amino acids
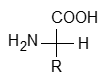
|
Name of the amino acid |
Characteristic feature of side chain, R |
Three letter symbol |
One letter code |
|
1. Glycine |
H |
Gly |
G |
|
2. Analine |
-CH3 |
Ala |
A |
|
3. Valine* |
(CH2 )2-CH- |
Val |
V |
|
4. Leucine |
(CH3 )2-CH-CH2 |
Lew |
L |
Configuration of α – Amino acids:
All α – amino acids except glycine are chiral molecules and exhibit optical activity. Most naturally occurring α – amino acids have L – configuration i.e., -NH2 group is on LHS as -OH group in L-glyceraldehyde.
However, α – amino exist in D and L forms.
Classification of Amino Acids:
(i) Acidic, basic and neutral amino acids:
Amino acids are classified as acidic, basic or neutral depending upon the relative number of amine and carboxyl groups in their molecule.
Equal number of amino and carboxyl groups make it neutral, more number of amino than carboxyl groups make it basic and more carboxyl as compared to amino make it acidic.

(ii) Essential and non-essential amino acids:
The amino acids which can be synthesized in the body are known as non-essential amino acids.
The human body can synthesize 10 out of 20 amino acids found in proteins. Those amino acids which can not be synthesized in the body but must be obtained through diet, are known as essential amino acids. The 10 essential amino acids are valine, leucine, isoleucine, arginine, lysine, threonine, methionine, phenylalasine, tryptophan and histidine.
These essential amino acids are required for the growth of our body and lack of these essential amino acids in diet can cause diseases such as Kwashiorkor.
Physical properties of α – amino acids:
(i) Amino acids are colourless, crystalline solids.
(ii) They are soluble in water and have high melting points.
(iii) They behave like salts rather than simple amines or carboxylic acids due to the presence of both acidic and amino group in the same molecule.
(iv) They are highly polar and in aqueous solution the carboxylic group transfer a proton to -NH2 group to give a dipolar ion which is called a Zwitter ion. Zwitter ion is a neutral species but contains both positive and negative charges.
The dipolar ion structure also called internal salt.
(v) In Zwitter ionic form amino acids show amphoteric behaviour as they reacts with acids and bases.
(a) In acidic solution, the carboxylate function (-COO–) accepts a proton and get converted to carboxyl substituent (- COOH). i.e., the ion becomes positive towards cathode in an electric field.
Therefore, the basic character of amino acid is due to – COO– group.
(b) In basic solution ammonium substituent changes to amino group (-NH2) by losing a proton i.e., amino acid exist as a negative ion & migrates toward anode in an electric field.
(vi) At a particular pH, the dipolar ion acts as neutral ion and does not migrates to cathode or anode.
This pH is known as isoelectric point of the amino acid. This is a characteristic of given amino acid. This is a characteristic of given amino acid and depends on the nature of R – group linked to α – carbon atom.
The isoelectric point depends on different groups present in the molecule of the aminoacid and neutral amino acids have isoelectric points in the range of pH 5.5 to 6.3.
At isoelectric point the amino acids have least solubility in water and this property is exploited in the separation of different amino acids obtained from the hydrolysis of proteins.
Chemical properties of α – amino acids:
Amino acids form salts with acids as well as with bases. Their chemical reactions are similar to primary amines and carboxylic acids. A summary of chemical properties is given below.
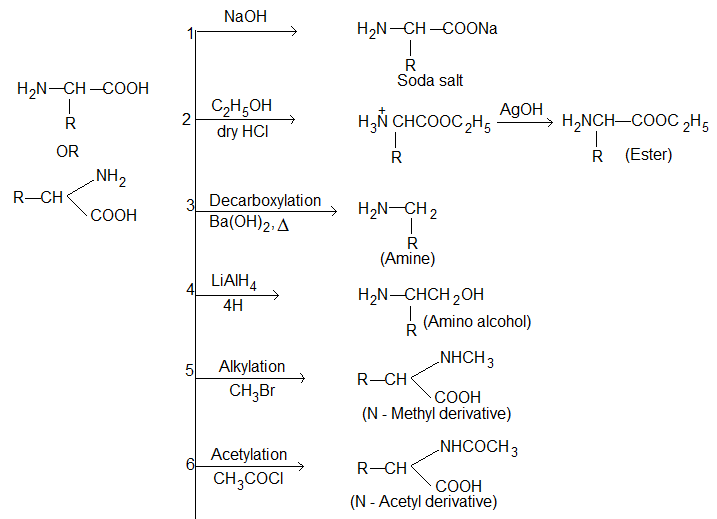

Action of heat:
(i) α – Amino acids lose two molecules of water and form cyclic amides.
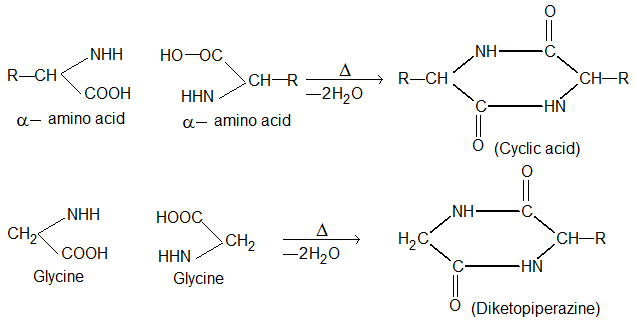
(ii) β – Amino acid lose a molecule of ammonia per molecule of amino acid to yield α, β-unsaturated acids.
(iii) γ – Amino acid and δ – amino acids undergo intramolecular dehydration to form cyclic amides called Lactams.
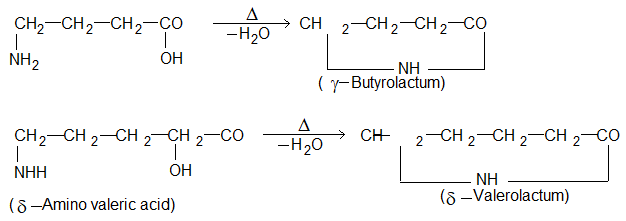
These lactums have stable five or six membered rings.
Illustration 5: Which a-amino acid can cross link peptide chains?
Solution: Cysteine can cross link peptide chains through disulphide bonds.
Formation of Protein:
a) Peptides and the peptide bond:
Proteins are formed by joining the carboxyl group of one amino acid to the α – amino group of another amino acid.
The bond formed between two amino acids by the elimination of a water molecule is called peptide bond or peptide linkage ( (-CO-NH-), is called peptides. E.g., when carboxylic group of glycine combines with the amino group of alanine, we get, glycylalanine.
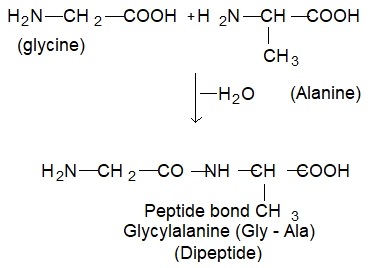
Alternatively the amino group of glycine may react with carboxyl group of alanine, resulting in the formation of a different dipeptide, alanyl glycine (Ala – Gly).
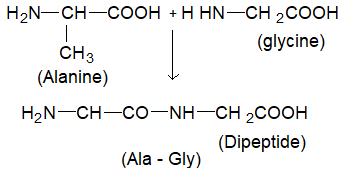
In both the dipeptides i.e., Gly – Ala or Ala – Gly, there are free functional groups at both ends. These groups can further react with the relevant groups of the other aminoacids forming tri, tetra, penta peptides and so on.
Thus, peptides are further designated as di, tri, tetra or penta peptides accordingly as they contain two, three, four or five molecules of same of different aminoacids, joined together by peptide linkages.
These are longer peptides.
In polypeptide structure free amino group (-NH2) known as N – terminal residue is written on the left hand side and the free carboxyl group (-COOH) known as C – terminal residue is written on right hand side of the polypeptide chain.
Ala – Gly – Ala (alanylglycylaalanine)
The name of any polypeptide starts with the N-terminal residue. The suffix ine is is replaced by yl for all amino acid part except the C – terminal residue. Hence, the above structure has the name alanyl glycyl alanine.
This no menclature is not used frequently. Instead, the three letter or one letter abbreviation for the amino acid is used. E.g., the above tripeptide is named as Ala – Gly – Ala or A – G – A.
Relatively shorter peptides are called digopeptides and longer peptides are known as polypeptides. A polypeptide with hundred or so many amino acid residues, having molecular mass higher than 10,000 is called a protein but this classification is not sharp. Polypeptides with fever amino acids are likely to be called proteins if they ordinary have well – defined conformation of a protein.
Polypeptides are amphoteric and they titrate as acids or bases and have an isoelectric point at which they are frequently least soluble and have the greatest tendency to aggregate.
Most of the toxins (poisonous substances) in animal venoms and in plant sources are polypeptides. Eligopeptides are effective hormones.
A dipeptide called asparture being 160 times sweeter to sucrose is used as substitute for sugar.
Aspartame
(Aspartyl phenylalanine methyl ester)
Each molecule of a given protein has the same specific sequence of the amino acids along its polypeptide chain and this imparts specific properties to a protein. Even a change of just one amino acid can drastically change the properties of entire protein molecule.
Haemoglobin consists of 574 amino acid units in its molecule in a definite sequence. When only one specific amino acid in the sequence is changed, it becomes a defective haemoglobin which loses its specific property of carrying oxygen in blood stream and results in a diseases called sickle cell anaemia.
Normal haemoglobin
– Val – His – Leu – Thr – Pro – Glu – Glu – Lys –
Sickel cell haemoglobin
– Val – His – Leu – Thr – Pro – Val – Glue – Lys –
Composition of proteins (Varies with source):
C = 50 – 53%
H = 6 – 7%
O = 23 – 25%
N = 17 – 17%
S = 1%
Other elements may also be present in protein.
e.g., P = in nucleoproteins
I = in thyroid proteins
Fe = in haemoglobin
Illustration 6: A tripeptide on complete hydrolysis gives glycine, alanine and phenyl alanine. Using three letter symbols write down the possible sequences of the tripeptide.
Solution: The possible combination can be
(i) Gly – Ala – Phe (ii) Gly – Phe – Ala
(iii) Ala – Gly – Phe (iv) Ala – Phe – Gly
(v) Phe – Gly – Ala (vi) Phe – Ala – Gly
Illustration 7: Amino acids have relatively higher melting points as compared to corresponding halo acids.
Solution: Amino acids exist as zwitter ions (dipolar ions). Due to zwitter ion structure amino acid behave like salts and have quite strong inter molecular forces. Hence, they have higher melting points as compared to corresponding haloacids which behave like normal molecular solids.
Structure of proteins:
Proteins are biopolymers containing a large number of amino acids joined to each other by peptide linkages and disulphide bonds having three dimentional structure.
Protein structures and shapes are studied at four different levels as
(i) Primary (ii) Secondary
(iii) Tertiary (iv) Quarternary structures
(1) Primary structure of protein:
Proteins may have one or more polypeptide chains. Each polypeptide in a protein has amino acids linked together in specific sequence. The number and sequence of the amino acids in its polypeptide chain refers to the primary structure of a protein.
Any change in this primary structure i.e., the sequence of amino acids creates a different protein.
e.g., Normal haemoglobin
– Val – His – Leu – Thr – Pro – Glu – Glu – Lys –
Sickel cell haemoglobin
– Val – His – Leu – Thr – Pro – Val – Glue – Lys –
In the patients suffering from sickle cell anemia, the defective haemoglobin in red blood cells precipitates causing the cells to sickel and some times even burst leading ultimately to death.
A protein containing a total of 100 amino acid residues is a very small protein, yet 20 different amino acids can be combined at one time in (20)100 different ways.
Primary structure of protein also tells about the location of disulphide bridge if any but tells us nothing about the shape or conformation of the molecule.
(2) Secondary structure of protein:
The secondary structure of a protein refers to the shape in which a long peptide chain can exist.
It gives information.
• about the conformation of segments of the back bone chain of a peptide or protein.
• About the manner in which protein chain is folded and bent.
Each molecule of a give protein has the same specific sequence of the amino acids along its polypeptide chain and this inparts specific
To minimum the energy a protein chain tends to fold in a repeating geometrical structure. This is based on three factors.
• the regional planarity about each peptide bond, which limits the possible confirmation of the peptide chain.
• Maximizing the number of peptide groups that engage in hydrogen bonding. Here hydrogen bonding operates between carbonyl oxygen of one amino acid and amide hydrogen of another aminoacid.
• Sufficient separation between nearly ‘R’ groups to avoid steric hindrance and repulsion of like charges.
Puling and Corey investigated the structures of many proteins with the help of x-rays patterns. It was observed that there are two different conformations of the peptide linkage present in proteins viz α-helix and β-conformation (coil conformation).
(i) α – helix structure:
In this structure of protein, formation of hydrogen bonds between substituted amide groups within the same chain causes the peptide chain to coil up into a spiral structures i.e., coils as a right handed screw and note that > Co & – NH groups of the peptide bond are trans to each other.
The α – helix model was proposed by linius pauling in 1951 on the basis of theoretical considerations was later verified experimently.
Due to the partial double bond character of the C-N bond in peptide linkage, the amide part, (i.e., -CO – NH -) is planar and rigid. Therefore, no free rotation about this bond is possible.
The free rotation of a peptide chain can only occur around the bonds joining the nearly planar amide groups to the α – carbon atoms as shown in the figure.
The angle (Φ and Ψ) through which rotations are possible are known as Ramchandran angles after the name of the Indian Biopaysicist, G.N.A. Ramachandran.
Hydrogen bonds between – N – H and > C = 0 groups of peptide bonds give stability to the structure. Thus, a structure having maximum hydrogen bonds hall be favoured.
Thus, α – helix form is the most common form in which a polypeptide chain forms all possible types of hydrogen bonds by twisting into a right handed screw (helix) with the – NH group of each amino acid residue hydrogen bonded to > C = 0 of an adjacent turn of the helix as shown in figure.
The α – helix is also known as 3.613 helia, since each turn of the helix has approximately 3.6 amino acid residue and a 13 member ring is formed by hydrogen bonding.
The helix is held in its shape primarily by hydrogen bonds between one amide group and carbonyl group which is 3.6 amino acids units away.
It may be noted that in proteins, the helix always has a right handed arrangement.
If you hold your hand so that the thumb points in the direction of travel along the axis of the helix, the curl of your fingers describe the direction in which the helix rotates.
All amino acids in a polypeptide chain have –configuration and therefore, it can only result in a stable helix of it is right handed.
Such proteins are elastic, i.e., they can be stretched. On stretching weak hydrogen bond break up and the peptide chain acts like a spring. The hydrogen bonds are reformed on releasing the tension.
α – helix structure protein is found in many proteins such as myosin (muscles), keratins (hair, wool, nails).
(ii) β – Pleated sheet structure:
This structure of protein was also proposed by linus pauling and co-workers in 1951.
In this conformation (structure) all peptide chains are stretched out to nearly maximum extension and then laid side by side, held together by intermolecular hydrogen bonds in zig – zag manner to form a flat sheet.
These sheets are sheets are stacked one upon another to form – three dimensional structure called β – pleated sheet structure.
The structure resembles the pleated fold of drapery and therefore is known as β – pleated sheet.
Two types of pleated sheets are possible, the polypeptide chain may run parallel i.e., the adjacent chains in the same direction, or may be antiparallel.
In other words, in parallel β – conformation N – termini are aligned head to head i.e., on the same side and in antiparallel β – conformation N – termini are aligned head to tail i.e., N – terminus of one chain and C – terminus of another chain are on the same side.
e.g., Keratin protein in hair has parallel β – sheet structure i.e., has parallel peptide chain and silk protein fibrion has antiparallel β – sheet structure i.e., antiparallel arrangement of the polypeptide chain.
(iii) Tertiary structure of protein:
This structure arises folding, coiling and bending of secondary structure. This structure gives the over all shape of proteins i.e., represents overall folding of the polypeptide chain. As a result fibrous and globular proteins are formed. Various linkage responsible for this tertiary structure are
• ionic interactions between oppositely charged groups i.e., and COO–, on the side chains.
• H – bonding
• Disulphide linkage (- CH2 – S – S – CH2 -).
• van der Waal’s interactions develop with charge functions between tow closely placed i.e., – CH2OH and – CH2
• Hydrophobic interaction, formed between two non-polar groups.
These are noncovalent hydrophobic interactions.
An example of disulphide bridge is found in insulin. Which consist of two polypeptide chains (A & B). Chain A consists of 21 amino acids and chain B consists of 30 amino acid with phenyl alanine at the N – terminals. Both the chains are cross linked by two disulphide bridges.
The fibrous proteins such as collagen and α – Keratins have large helical content and have rod-like rigid shape and are insoluble in water. The structure of collagen triple helix is shown in figure.
On the other hand, in globular proteins such as haemoglobin the polypeptide chains consist pertly of helixal sections which are folded about the random cuts to give a spherical shape.
Perute and Knedrw determined the tertiary structure of haemoglobin and myoglobin through X- rays and wore awarded Noble Prize in 1962.
(iv) Quarternary structure:
Many proteins exist as a single polypeptide chain but there are some proteins, which exist as assemblies of two or more polypeptide chains are called Oligomers but the individual chains are called sub units or protomers. These sub units may be identical or different and are held together by non-covalent forces such as hydrogen bonds, electrostatic interactions and van der Waal’s interactions.
If a protein has six subunits the arrangement in space may be as shown below.
Thus, quanteranary structure of protein refers to the determination of the number of sub units and their arrangement in an aggregate protein molecule.
The best known example of a protein possessing quaternary structure is haemoglobin which transport oxygen from the lungs to he cells and carbondioxide from the cells to the lungs through the blood stream. It is an aggregate of four polypeptide chains or sub units i., two identical α – chains each containing 141 amino acid residues and two identical β- chains each containing 146 amino acid residues.
Classification of proteins:
(A) On the basis of hydrolysis products 6 – chemical composition:
Based on the type of products formed on hydrolysis, the proteins may be divided into three classes.
(i) Simple proteins: These proteins are composed of chains of α – amino acid units only joined of α – amino acids on hydrolysis with acids or enzymes.
The important examples are: albumen’s, globulins, glutalins, prolamines, Keratin, etc.
(ii) Conjugated proteins: These are proteins which on hydrolysis give a non-protein part and α – amino acids. Thus, these are formed by the combination of simple proteins with some non-protemous part. The non-protemous part is called prosthetic group and it controls the biological functions of the protein. The common prosthetic groups in the proteins are
|
Name of Protein |
Prosthetic group/Cofactor |
|
Nucleoproteins |
Nuclic acids |
|
Glycoproteins |
Sugars |
|
Lipoproteins |
Lipid such as lecithin |
|
Phosphoproteins |
Phosphoric acid |
|
Chromoproteins |
Figments containing some metals e.g., Haeme in haemoglobin containing Fe and Cu. |
These proteins on hydrolysis yiled amino acids and non-protein material. The main function of the prosthetic group is to control the biological functions of the protin.
(iii) Derived proteins: These are the degration products obtained by partial hydrolysis of simple or conjugated proteins with acids, alkaties or enzymes. Some examples are proteoses, peptones and polypeptide.
Proteins → Proteoses → Peptone → Polypepted → α – amiacids.
(B) Classification of proteins on the basis of molecular shape:
According to molecular shape, proteins are divided into two types.
• Fibrous proteins: These are made up of polypeptide chains that run parallel to the axis and are held together by strong hydrogen and disulphide bonds. They can be stretched and contracted like a thread. These are casually insoluble in water. The common examples of fibrous proteins are Keratin of skin, hair, nails, wool, collagen of tendons, fibrous of silk, myosin of muscles etc.
• Globular proteins: These have more or less spherical shape (compact structure) and polypeptide chain in these proteins are folded around itself in such away as to give the entire protein molecule an almost globular or 3D spheroid shape. α – helixs are tightly held up by weak attractive forces of various types i.e., hydrogen bonding, disulphide bridges, ionic or salt bridges.
The common examples of globular proteins are insulin (hormone), pepsin, haemoglobi, cytochromes, albumins etc i.e., enzymes and hormones.
|
Globular proteins |
Fibrous proteins |
|
(i) These proteins are cross linked condensation products of basic and acidic amino acids. |
(i) These are linear condensation product. |
|
(ii) These are soluble in water, mineral acids bases. |
(ii) These are insoluble in water but soluble in strong acid and bases. |
|
(iii) These proteins have 3D folded structure. These are stabilized by internal hydrogen bonding. |
(iii) These are linear polymers polymers held together by inter molecular hydrogen bonds. |
|
(iv) Ex- Albumins (egg), all enzymes and hormones. |
(iv) Ex. Myosin (muscle), Keratin (hair), fibroin (silk), collagen (tendons) |
Proteins can also be classified on the basis of their functions.
|
Protein |
Functions |
Examples |
|
(i) Enzymes |
Biological catalyst, vital to all living systems. |
Trypsin, pepsin. |
|
(ii) Structural proteins |
Proteins that hold living systems together. |
Collagen |
|
(iii) Hormones |
Act as messengers |
Insulin |
|
(iv) Transport proteins |
Carry ions or molecules from place to another in the living system. |
Haemoglobin |
|
(v) Protective proteins (antibiotics) |
Destroy any foreign substance released into the living system poisonous in nature. |
Y – blobulin |
|
(vi) Toxins |
Poisonous in nature |
Snake venous |
Denaturation of proteins:
The most energetically stable of a protein is called its native state. The structure of the natural proteins is responsible for their biological activity. These structures are maintained by various attractive forces between different parts of polypeptide chains.
The breaking of these forces by a physical or a chemical change makes the proteins to lose all or part of their biological activity. This process is called denaturation of protein i.e., A process that changes the physical and biological properties of proteins with affecting the chemical composition of a protein is called denaturation.
The denaturing of proteins can be done by adding chemicals, such as acids, basis, organic solvents, heavy metal ions or urea. It can also be done with the help of heat and ultraviolet light.
Denaturation can be irreversible or reversible. In irreversible denaturation the denatured protein does nor eturn to its original shape. Renaturatio is the most common example of denaturatio of protein is the coagulation of albumin present in the white of as egg. Proteins present in egg white are globular and soluble. When an egg is boiled in water the globular proteins presents in it change to rubber like insoluble mass. This is irreversible denaturation and the protein can not return to its original state.
(ii) The coagulation of milk in the presence of an acid (lemon juice) to form cheese is also an example of denaturation of proteins. During this denaturation globular milk protein lactoalbumin become fibrous.
Test of Proteins:
(i) Biuret test: On adding a dilue solution of coppersulphate to alkaline solution of protein, a violet colour is developed. This test is due to the presence of peptide (-CO – NH-) linkage.
(ii) Xanthoprotic test: Some proteins give yellow colour with concentrated nitric acid (formation of yellow stains on fingers while working with nitric acid in laboratory). The formation of yellow colour is due to the reaction of nitric acid with benzenoid structure. Thus, when a protein solution is warmed with nitric acid yellow colour may be developed which turns orange on addition of NH4OH solution.
(iii) Million’s test: When million’s reagent (Mercurous and mercuric nitrate in nitric acid) is added to a protein solution, a white precipitate which turns brink red on heating may formed. This test is given by proteins which yield tyrosine on hydrolysis. This is due to presence of phemolic group.
(iv) Ninhydrin test: This test is given by all proteins. When a protein is boiled with a dilute solution of ninhydrin, a violet colour is produced.
(v) Molisch’s test: This test is given by those proteins which contain carbohydrate residue. On adding a few drops of alcoholic solution of a – naphthol and concentrated sulphuric acid to the protein solution, a violet ring is formed.
Enzymes: The enzymes are biological catalysts produced by living cells which catalyze the biochemical reactions in living organisms. Chemically enzymes are naturally occurring simple or conjugate proteins. Some enzymes may be non-proteins also.
The important enzymes are
|
Enzyme |
Reaction catalysed |
|
1. Maltase |
1. Maltose → Glucose + Glucose |
|
2. Lactase |
2. Lactose → Glucose + Galactose |
|
3. Amylase |
3. Starch → n Glucose |
|
4. Invertase |
4. Sucrose → Glucose + Fructose |
|
5. Urease |
5. Urea → CO2 + NH3 |
|
6. Carbonic anhydrase |
6. H2CO3 → CO2 + H2O |
|
7. Repsin |
7. Proteins → Amino acids |
|
8. Trypsin |
8. Proteins → Amino acids |
|
9. Nuclease |
9. DNA, RNA → Nuclotides |
|
10. RNA polymerase |
10. Ribonucleotide → RNA |
|
11. DNA polymerase |
11. Deoxyribonucleotide → DNA triphosphate |
Nucleic Acid: Every living cell contains nuceloproteins, substances made up of proteins combined with biopolymers of another kind known as nucleic acids.
Nucleic acids are long chain polymers (polynucleotides) of nucleotides with a polyphosphate ester chain while proteins have a polyamide chain.
These are mainly of two types, the deoxyribonucleic acid (DNA) and ribonucleic acids (RNA).
In higher cells, DNA is localized mainly in the nucleus, within the chromosome. A small amount of DNA is present in the cytoplasm also where it is obtained in mitochondria and chloroplast.
RNA is also present in nucleus as well as cytoplasm.
DNA is the major source of genetic information, which is copied into RNA molecules (Transcription).
Chemical composition of nucleic acids:
Complete hydrolysis of DNA or RNA yields a pentose sugar i.e., ribose in RNA yields a pentose sugar i.e., ribose in RNA and deoxyribose in DNA, two types of heterocyclic nitrogenous bases viz purine and purimidine bases along with phosphoric acid. So the sugars are differ only at carbon atom 2 in the ring.
DNA contains the purine bases adenine (A) & guanine (G) and pyrimidine pyrimidine bases thymine (T) and cytosine (C) while RNA contain uracil (U) in place of thymine base.
DNA
RNA
It is noted that purines have two fused rings and pyrimidines have a single heterocyclic ring.
Nucleosides (Pentose sugar + N – Base):
The N – glysides of purine or pyrimidine bases with pentose sugars are known as nucleosides.
Bas + sugar → Nucleoside.
Naming: Nuclotides are named as adenosine; guanosine, cytidine, thymidine and uridine respectively.
In nuclosides the sugar carbons are primed ( ‘ ) in order to distinguish them from those of bases.
The purine or pyrimidine bases are attached to position 1’ of protoses through N – glycosidic linkages (bonds).
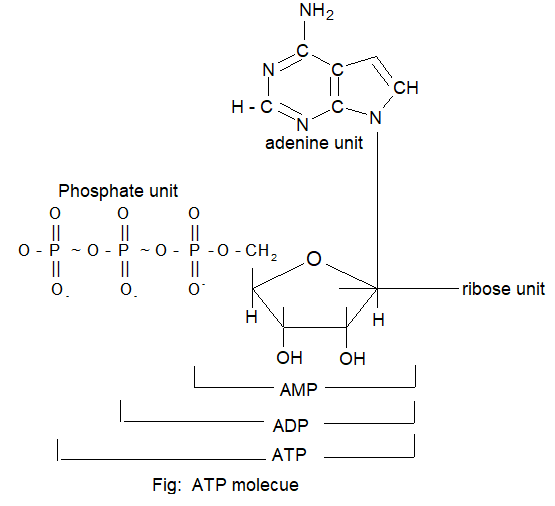
Nucleotides: A nucleotide is a phosphate ester of nucleoside and consist of a purine or pyrimidine bases, the 5 – carbon sugar and one or more phosphate groups.
Thus, nucleotides contains a base moiety, sugar moiety and phosphate group.
The nucleotides are abbreviated by three capital letters, preceded by d – increase of deoxy series e.g.,
AMP ⇒ adenosine monophosphate
dAMP ⇒ deoxy adenosine monophosphate
ADP ⇒ adenosine diphosphate
UDP ⇒ uridine diphosphate etc.
Similarly we get deoxy adenosine monophosphate dAMP, dADP, DATP and so on.
It is also shown that nucleotides are joined together by phosphodiester linkages between 5′ and 3′ carbon atoms of pentase sugar i.e., 5′ and 3′ in case of deoxyribose & 5′ and 3′ or 2′ in case of ribose sugar.
The formation of typical dinucleotide is shown in figure.
Nucleic acids contain a chain of 5 membered ring sugars linked by phosphate groups and each sugar molecule is bonded to a heterocyclic amine by a β – glycosidic bond.
A dinuclotide contains two nucleotide subunits, a digonucleotide three to ten and a polynucleotide many sub units. E.g., DNA and RNA are polynucleotides.
A nucleic acid chian is commonly abbreviated by a one letter code with the 5′ end of the chain written at the left.
e.g., a trinucleotide having adenosine, cytosine, guanine bases and a tetra nucleotide having adenine, cytosine, guanine and thymine bases from 5′ end to 3′ end are represented as – ACG and ACGT respectively.
Nitrogenous bases, combining with pentose sugars and a phosphate group, from eight types of nucleotides i.e., four for DNA and four for RNA.
Thus, the sequence in which the four nitrogen bases are attached to the sugar phosphate backbone of a nucleotide chain is called the primary structure of nucleic acid.
Double Helix structure of DNA (Watson Crick Model):
Wilkins (1953) from their x-ray studies showed that DNA molecule has a helical / spiral form and the helix contains two twisted strands.
E.chargaff found that base composition in DNA varied from one species to other species but in all cases the amount of adenine equal to thymine (A = T) and the amounts of cytosine and guanine were also found to be equal (G = C).
Therefore, the total amount of purines are equal to the total amount of pyrimidines (A + G = C + T).
However, the AT/CG ratio varies from species to species. E.g., this AT/GC ratio is 1.52 in human while in E.Coli it is 0.93.
In 1953, based on the X-ray diffraction studies of DNA, J.D. Watson and F.H.C. Crick proposed a double helical structure for DNA. This structure explains the base equivalene (A = 7, G = C) as well as other properties of DNA like duplication or replication in living cell.
The double helix of DNA is composed of two right handed helical polynucleotide chains (stand) coiled around the same central axis i.e., Plectonemic coils.
The two stands are antiparallel and their (5′ → 3′) phosphodiester linkages run in opposite directions.
The bases are stacked inside the helix in planes in a perpendicular direction to the helical axis is base pair are planar and parallel to each otheron the inside of the helix.
It is like a stack of flat plates held together by two ropes of sugar – phosphate polymeric backbone running along outside of stack.
The two strands (nucleotides) are held together by hydrogen bonds.
Only two base pairs that is AT and CG fit into this structure because A pairs with T but not cytosine because A forms two hydrogen bonds with T (A = T) but there is not hydrobond between A and C. Similarly G forms three hydrogen bonds with C but only one hydrogen bond with T.
All these hydrogen bonds are almost of same bond lengths and CG base pair has more stability as compared to AT base pair.
Aero both the strands are not identical but because of base pairing are complimentary to each other.
In addition to hydrogen bonds other forces like hydrophobic intractions between stacked bases are also responsible for stability and maintenance of double helix.
The primary structure of nucleic acids tells about the sequence of bases in the strand while secondary structure gives the double helix.
The double helix resembles a ladder with the base pairs as the rungs.
The diameter of double helix is 2nm = 20Å and the double helical structure repeats at intervals of 3.4nm 34Å (one complete turn) which corresponds to ten base pairs. The spacing between adjacent base pairs is 3.4 Å along helical axis and are related by a rotation of 360S.
Two kinds of grooves one major and one minor are evident in the helical structure.
Though, DNA helices can be both right handed and left handed. The β-configuration of DNA with right handed helices is the more stable.
When DNA is heated the two strands separate out from each other (known as melting) and on colling these again hybridige. This is known as annealing.
The temperature at which the two strands separate completely is known as its melting point ™, which is specific for each specific sequence.
As regards the secondary structure of RNA, helices are present but single stranded.
Heredity – the Genetic code:
Nucleic acids control heredity at molecular level.
The two DNA strands are complementary and both strands carry the same genetic information. i.e., double helix of DNA is the store house of hereditary information of the organism.
Both strands serve as templates fro the synthesis of complementary new strans.
The new daughter DNA molecules are identical to the original and contain all the original genetic information. These informations are in coded form as the sequence of bases along the polynucleotide chain.
DNA has only four different bases, therefore, the genetic message can be compared to language which has only four letters A, C, G and T.
DNA preserve the information and uses in the following manner.
(i) DNA molecules can duplicate themselves so that they can synthesise another DNA molecules identical with the original. This process is called replication. In other wood the synthesis of identical copies of DNA is replication.
(ii) A single strand of DNA can act as a template on which a molecule of RNA is synthesized in a specific manner and the process is called transcription.
(iii) The RNA molecule in turn directs the synthesis of specific proteins which are characteristic of each kind of organisms and this process is called translation.
These concepts constitute the central dogma of molecular biology and were summarized by prancis crick in the following diagram.
It may be noted that translation is unidirectional but transcription may some time be reversed. i.e., RNA may be copied into DNA.
This reverse transcription occurs during life cycle of some retroviruses.
Thus, the base sequence in DNA controls the sequence of amino acids in the protein and therefore, the hereditary. The hereditary message is written in a language of only 4 – letters, in a code with each word of 3 letters (triplet called codon) standing for a particular amino acid.
In order to understand fully the genetic code, let us first learn about replication and transcription.
Replication:
The process by which a single DNA molecule produces two identical copies of itself is called replication or cell division. So, DNA has this unique property of duplication itself.
Replication of DNA is an enzyme catalyzed process. In enzyme catalyzed nucleic acid synthesis, the synthesis of DNA takes place in a region of the molecule where the strands have started to separate called replication fork.
The genetic information for the cell is coded in the sequence of bases Adenine (A), Thymine (T), Guanine (G) and cytosine (C) in the DNA molecule.
During division of the cell, DNA molecule replicate and produce exact copies of themselves.
Each daughter cell has DNA molecules identical to that of the parent cell.
DNA replication takes place only in the 5′ → 3′ direction.
Therefore, one strand of DNA is synthesized continuously in a single piece in the 5′ → 3′ direction. The order strand of DNA is synthesized discontinuously in small pieces which are finally joined together by an enzyme called DNA ligase.
Thus, each of the two daughter molecules of DNA that results contains one of the original strands and other newly synthesized stand. Thus, this process is called semi conservative replication.
The genetic information of human cell is contained in 23 pairs of chromosomes. Each chromosome is composed of several thousand genes (segment of DNA). It has been estimated that the total DNA of a human cell (human genome) contains 2.9 billion base pair.
Transcription:
The transcription involves copying of DNA sequence into a completary RNA molecule called messenger RNA.
A portion of DNA double helix strand is unwound and one of the two DNA strands acts as the template for the synthesis of RNA molecule called mRNA.
RNA is much shorter than DNA and is generally single stranded.
Although DNA molecules can have billions of base pairs while RNA molecules have rarely more 10,000 nuclotides. There are three types of RNA known as messenger RNA (mRNA), ribosomal RNA (rRNA) a structural component of ribosomes and transfer RNA (tRNA), the carrier of amino acid for protein synthesis.
This transcription process resembles DNA replication, the sequence of DNA base provides the blue print for the synthesis of mRNA. The synthesis of mRNA from a DNA blue print is called transcription and this takes place in the nucleus of the cell.
The newly synthesized mRNA can then leave the nucleus carrying the genetic information into the cytoplasm, the cell material outside the nucleus where translation of this information into proteins takes place.
DNA contains sequence of bases known as promoter sites. The promoter sites are bound to enzyme initiating RNA synthesis the DNA at a promoter site unwinds to give single strands exposing the bases. One of the strand is called sense strand or informational strand. The complementary strand is called the template or antisense strand.
The base in the template strand specify the bases that need to be incorporated into mRNA, following the same base pairing found in DNA. E.g., Each guanine in the template strand specifies the incorporation of a cytosine (C) into mRNA and each adenine (A) to a uracil (V) of mRNA as RNA does not contain thymine (T) but contain uracil (U).
|
Unbound DNA: |
G |
C |
A |
C |
T |
T |
A |
G |
|
New mRNA: |
C |
G |
U |
G |
A |
A |
T |
C |
Translation (Protein synthesis):
Translation is the process by which the genetic message in DNA that has been passed to mRNA is decoded and used to build proteins.
Transcription is copying within the same language of nucleotides and translation changing to other language, the language of amino acids.
A protein is synthesized from its N-terminal end to its C – terminal end by the sequence of bases along mRNA strand in the 5′ → 3′.
This process occurs with the attachment of mRNA to the very small ribosome particles in the cytoplasm with the involvement of t-RNA.
The m-RNA them gives the message of the DNA and dictates the specific amino acid sequence for the synthesis of protein. The four bases in m-RNA that is A, C, G and U act in the form of triplet or set of three and each triplet acts as a code for a particular amino acid.
Since, it is the sequence of four different nucleotides that is used to convey information for the combination of twenty different amino acids into peptide chains, each amino acid must be represented by combination of at least three nucleotides (triplet).
This is true because there are only 16 doublets of four nucleotides (42) but there are 64 triplets (43). These 64 three letter code words are known as codon.
Every t-RNA molecule has an amino acid attachment site and a site having three complementary nucleotides for recognition of the triplet in m-RNA (anticodon).
The genetic code has four important features;
• It is universal
• It is commoless
• It is degenerate i.e., more than one codon for one amino acid and
• The third base in the codon is not always specific.
There is a single code for all living organisms. This is a strong indication that life started on earth about 3 billion years ago and only once the genetic code was established has remained unchanged since then.
Illustration 8: What anticodon sequences on the mRNAs are coded for by the mRNAs in the following base sequence:
CUU – AUG – GCU – UGG – CCC – UAA
Solution: Since anticodon sequence of tRNA are complementary to the codon sequence on mRNA; anticodon sequence is
GAA – UAC – CGA – ACC – GGG – AUU
Lipids:
The terms lipid was introduced by German Biochemist Bloor in 1943.
Lipids are naturally occurring compound related to fatty acids and include oils, fats, waxes (like steroids, terpenes, phospholipids & glycolipids.
These are hydrophobic in nature and hence, are insoluble in water but are soluble in organic solvents such as chloroform, ether, etc.
The lipids are important constituents of diet.
In the body the fats serves as an efficient source of energy and are stored in the adipore tissues.
Phospholipids (lipids containing phosphorus) are important constituents of cell membrane.
Classification of Lipids:
Based on their chemical composition, lipids are classified as
1) Simple lipids (homolipids): These are esters of long chain fatty acids with alcohols, which include, neutral fats and waxes.
(i) Neutral fats glycerides: These are also known as triglycerides and are trimesters of fatty acid with glycerol. These are important constituents of our diet and serve as efficient source of energy.
(ii) Waxes: These are esters of fatty acids with long chain monohydroxy alcohols. These have higher melting points than neutral fats.
2) Compound lipids (heterolipids): Lipids with additional groups (in addition to esters) are called compound lipids. On hydrolysis they give fatty acids, alcohols and other compounds.
These include:
• Phospholipids (phosphatides): Lipids with additional groups such as phosphoric acid, nitrogen containing bases and other substituents are called phospholipids.
• Glycolipids: These are asters of fatty acids with carbohydrates and may contain nitrogen but no phosphorus.
3) Derived lipids:
These are the substances derived from simple and compound lipids by hydrolysis. These include fatty acids, fatty alcohols, mono and diglycerides, steroids, terpenes and carotenoids. These are some times present as waste products of metabolism.
Glycerides and cholesterol ester are also called neutral lipids since these do not carry any change.
Chemical structure and properties of lipids:
Simple lipids:
(i) Glycerides: Oils and fats are simple lipids. These are most abundant lipids. These are esters of glycerol and three long chain fatty acids and are simply known as triglycerides/glycerides. The three fatty acids in triglycerides may be identical or different. The naturally occurring fatty acids always contain an even number of carbon atoms and may be saturated or unsaturated. E.g., (i) saturated fatty acids.
Lauric acid :
Myristic acid :
Palmitic acid:
Stearic acid :
(ii) Unsaturated fatty acids (contains one or more double bonds):
In most centuared acids double bond is present all C – 9. This is designated as not conjugated. Some acid contain more than one double bond. These doubl bonds are not considered.
Oleic acid :
Linoleic acid:
Linonic acid:
The glycerides containing large portion of saturated acid solid at room temperature and called fats. E.g., tripalmitin and tristearin.
On the other hand, the glycerides containing large proportion of unsaturated acids are liquid at room temperature and are called oils.
e.g., triolein and α – oleo – β – palmito – α – stearch (mixed triglyceride).
(ii) Waxes:
These are ester of long chain saturated and unsaturated fatty acids with long chain monohydroxy alcohols and are more lipids. The fatty acids range between C14 and C36 and the alcohols range from C16 to C36. Most of the waxes are mixtures.
Biological functions and other applications of lipids:
Oil and fats are one of the main source of food for living organism. The main functions of lipids are:
• Simple lipids act as important source of energy in our food supply. They are even richer sources of energy than carbohydrates. g., 1g of fats on oxidation gives 37kJ of energy whereas 1g of carbohydrates provides only 17 kJ of energy’
• Phospholipids serve as structural material of cells and tissues such as cell membrane. These are also used as detergents to emulsify fat for transport within the body. These are never stored in large amounts.
• Cholesterol is the principal sterol of higher animals and is abundant in nerve tissues and gallastones. Cholesterol is not present in plant fats.
• Simple lipids can act as heat insulators and shock absorbers for the living plant fats.
• Lipids are essential for the absorption of fat soluble vitamins such as A, D, E and K.
• Some fats supply essential fatty acids.
Illustration 9: Which group in phospholipids is hydrophilic?
Solution: Phosphate group.
Hormones:
Hormones are low molecular weight substances (molecules) that transfer information from one group of cells to distant tissue or organ i.e., these are cheimical messengers. The term hormone was first used by William Baylers and Earnest starling in 190 – 1504 for secretin produced by intestinal mucosa.
These substances are produced in small amounts by various endocrine (ductless) glands in the body and delivered directly to the blood stream in minute quantities and are carried by blood to various target organs where these exert physiological effect and control metabolic activities. Thus, the tissues or organs where they are produced are called as effectors and those where the exert their influence as targets. The hormone receptors are all proteins.
Therefore, frequently their site of action is away from their origin. They are required in trace amounts and are highly specific in their function.
As they are readily oxidized, their effects do not remain permanent unless these are supplied continuously i.e., the deficiency of any hormone leads to a particular disease, which can be cured by the administration of that hormone.
Hormones control cell and tissue growth, heart beat, blood pressure, secretion of digestive enzymes, kidney function the reproductive system etc.
In mammals, the secretion of the hormones is controlled by anterior lobe of the pituitary gland located at the base of brain. These hormones are then carried to other gland such as adrenal, cortex and sex glands to stimulate the production of other hormones.
Classification of hormones:
(i) Based on their site of action, the hormones are of two types

(ii) Based on the structure of hormones, these are classified as steroids and non-steroids as:
Steroid hormones:
These hormones contain a steroid nucleus which is based on four ring network consisting of three cyclohexane rings and one cyclopentange ring.
The steroid nucleus found in some vitamins drugs and bile acids also.
These steroid nucleus and a few sex hormones are give below.
Functions of hormones:
(A) Functions of steroid hormones:
(1) Functions of sex hormones:
Sex hormones are divided into three groups.
• Male sex hormones, or androgens e.g., testosterone.
• Female sex hormones or estrogens e.g., estradiol, estron
• Pregnancy hormones or progestines.
(a) Testosterione C19H28O2: Is the major male sex hormone produced by testes. These are responsible for male characteristics such as deep voice, facial hair, general physical constitution during puberty. Synthetic testosterone analogs are used as medicine to promote muscle and tissue growth. E.g., in patients with muscular atrophy.
Unfortunately, such steroids are also abused and consumed illegally, most commonly by body builder and athletes, however these have numerous health risks.
(b) Estradiol (aestrogen) is the main female sex hormone. It is responsible for development of secondary, female characteristics and participates in the control of the menstrual cycle (me)
(c) Progesteron (a progestin) is responsible for preparing the uterus for pregnancy. Many steroid hormones such as progesterone itself has played significance role as birth control agents.
(2) Functions of Adrenal cortical hormones (corticosteroids):
These are produced by cortex of the adrenal glands. Their production is controlled by the hormones of the anterior lobe of the pituitary gland.
(a) Mineralo corticoids made by different cells in the adrenal cortex are concerned with water salt balance in the body. These regulate NaCl content of blood and cause excretion of K in urine.
(b) Glucocorticoids, made by adrenal cortex, modify certain metabolic reactions and have an anti-inflammatory effect.
(B) Functions of non-steroid hormones:
(1) Peptide hormones:
These hormones contain a peptide chain. These are secreted by the posterior lobe of the pituitary gland. For example : insulin is an important peptide hormone and has important (profound) influence on carbohydrate metabolism. It facilitates enthy of glucose and others sugars into the cells, by increasing pentration of cell membranes and augmenting phosphorylation of glucose. It controls the metabolism of glucose and maintains glucose level in the blood. i.e., this decreases glucose concentration in blood and therefore insulin is commonly known as hypoglycemic factor. It promotes anabolic process and inhibits catabolic processes.
Its deficiency in human beings causes diabetes mellitus.
Insulin isolated from itlets of Langerhans or is let tissue of pancrease was the first hormone to be recognized as protein.
Sanger got Nobel prize in 1958 for determing the structure of insulin.
(2) Functions of amino acid derivatives:
These are water soluble compounds which are structurally derived from amino acids. The common examples are thyroidal hormones such as thyroxin and tri-odothyronine effect the general metabolism, regardless of the nature of their specific activity. Therefore, the thyroid gland is known as pace setter of the endocrine system.
Illustration 10: How are hormones transported to the target tissues?
Solution: Hormones are produced in ductless glands and are transported to target tissues through the circulation of blood.
Vitamins:
These are essential diatrary factors required by an organism in minute quantities for the normal health, growth and maintenance of body.
They are chemically different from the main nutrients, fats, carbohydrates and proteins.
The deficiency of these vitamins causes specific deficiency disease. Multiple deficiencies caused by lack of more than one vitamins are more common in human beings. This condition of vitamin deficiency is known as avitaminoses.
The actual formulae of vitamins are very complicated for the sake of simplicity, these are designated by alphabets, A, B, C, D, E and K. Any subgroup of individual vitamins is designated by the number subcrept e.g., B1, B2, B6, B12.
Source of vitamins:
Plants can synthesize almost all vitamins whereas only a few vitamins are synthesized in animals.
Vitamin D may be supplied through food or may be produced in the skin by irradiation of sterols with sunlight (ultraviolet light).
Human body can synthesize vitamin A from carotene and some members of vitamin B – complex and vitamin K are synthesized by microorganisms present in intestinal tract.
Vitamins are widely distributed in nature both in plants and animals.
All cells in the body can store vitamins to some extent. However, most of the vitamins have been synthesized and are available commercially. These are effective when taken orally.
Classification of vitamins:
Vitamins are generally classified into two broad type based on their solubility in fat and water i.e., fat soluble & water soluble.
(1) Fat soluble vitamins:
These are only substances readily soluble in fats.
This group includes vitamins A, D, E and K.
Liver cells are rich in fat soluble vitamins such as A and D.
This group of hydrophobic, lipid soluble vitamins are not absorbed in the body unless fat digestion and absorption proceed normally.
Their deficiency can cause malabsorptive disease.
Excess intake of these vitamins may causes hypervitaminoses.
(2) Water soluble vitamins:
Includes the remaining hydrophilic vitamins i.e., vitamins B – couple & vitamin C etc.
These water soluble vitamins are stored in much lesser amounts in the cells.
Note: Vitamin H (Biotin) is neither soluble in fat, nor in water.
Functions of vitamins:
1) Vitamin A: The chemical name of vitamin A is retinol. It is fat soluble vitamin. It is also called bright eye vitamin.
Functions:
• It helps in proper growth and normal skeletal development of the body.
• It plays an important role in maintaining proper vision.
• It is also essential for healthy teeth structure.
• It helps in the maintenance of healthy, glowing soft skin.
2) Vitamin B: It consist of 11 substances of these vitamins B1, B2, B4, B6 and B12 are important.
(a) Vitamin B1 : The chemical name of B1 is thiamine
(i) It helps in carbohydrates metabolism.
(ii) It helps in carbohydrate and protein metabolism.
(iii) It is necessary to keep the skin healthy.
(iv) It helps in the normal functioning of the eye.
Illustration 11: Fresh tomatoes are a better source of vitamin C than those present in tomatoes which have been stored for some time.
Solution: On prolonged exposure to air, vitamin ‘C’ present in stored tomatoes is destroyed due to its aerial oxidation.
SOLVED PROBLEMS-1
Prob 1: What are carbohydrates?
Sol: Carbohydrates are polyhydroxy aldehydes or ketones or substances which on hydrolysis yield.
Prob 2: Give two functions of carbohydrates.
Sol: (i) Carbohydras act as biofuels and provide energy.
(ii) They are the structural components of the cells.
Prob 3: What functional group is present in a ketose? Give one example.
Sol: Ketone group is present. Fructose is an example of ketose.
Prob 4: What are anomers?
Sol: Anomers are pair of structures which differ only in the orientation of the hydroxyl group at C1. They are formed because C1 in the formation of ring structure in glucose becomes chiral, thus, giving two different confirmations.
Prob 5: What are the constituent units of cellulose?
Sol: b-glucose. Cellulose contains D-glycopyranoside units linked in 1 : 4 fashion in very long unbranched chains.
Prob 6: Give one example each of a reducing and a non-reducing sugar.
Sol: Reducing sugar: Glucose, Non-reducing sugar : Sucrose.
Prob 7: What is a peptide bond?
Sol: The amide bond, , in proteins is called a peptide bond.
Prob 8: In what respect do the naturally occurring amino acids differ from each other?
Sol: They differ with respect to the alkyl group.
Prob 9: What do you understand by essential amino acids?
Sol: In all about 20 amino acids are known to occur in nature, out of which ten amino acids are essential for the human body for the growth and cannot be synthesized by the body. They are called essential amino acids.
Prob 10: What is isoelectric point?
Sol: The pH at which the structure of an amino acid has not net charge is called its isoelectric point, pI.
SOLVED PROBLEMS-2
Prob 1: Enzymes belong to which of the following class of compounds?
(A) Polysaccharides
(B) Polypeptides
(C) Polynitroheterocyclic compounds
(D) Pyrimidine bases
Sol: (B) Enzymes belong to the class of Polypeptides.
Prob 2: Thymin is a
(A) Pyrimidine (B) Purine (C) Carbohydrate (D) Vitamin
Sol: (A) Thymin is a Pyrimidine base.
Prob 3: Peptides upon hydrolysis give
(A) Amines (B) Amino acids (C) Ammonia (D) None of these
Sol: (B) Peptides on hydrolysis give amino acids.
Prob 4: Fructose is a
(A) Aldose (B) Ketose (C) Both aldose and ketose (D) None of these
Sol: (B) Fructose is a ketose.
Prob 5: Metabolic activities of cells are controlled by
(A) Proteins (B) DNA (C) RNA (D) Fat
Sol: (B) Metabolic activities of cells are controlled by DNA.
Prob 6: Glucose reacts with X number of molecules of phenyl hydrazine to yield osazone. The value of X is
(A) Three (B) Two (C) One (D) Four
Sol: (A) Glucose reacts with X number of molecules of phenyl hydrazine to yield osazone. The value of X is three.
Prob 7: Which of the following gives maximum energy in metabolic processes?
(A) Proteins (B) Vitamins (C) Lipids (D) Carbohydrates
Sol: (C) Lipids give maximum in metabolic processes.
Prob 8: Vitamin B1 is
(A) Riboflavin (B) Cobalamin (C) Thiamine (D) Pyridoxine
Sol: (C) Vitamin B1 is thiamine.
Prob 9: Which one gives positive silver mirror test?
(A) Sucrose (B) Glucose (C) Starch (D) Fructose
Sol: (B) Glucose gives positive silver mirror test.
Prob 10: Which one is the complementary base of adinine in one strand to that in other strand of DNA?
(A) Guanine (B) Gutocine (C) Thymine (D) Uracil
Sol: (B) Thymine.